AndroidでLLMをローカル実行!llama.cppで始めるオフラインAI開発
世の人々のすなる生成AI開発といふものを...。 生成AIを活用したアプリ開発ではサーバ側APIを呼ぶ構成が主流ですが、端末内で完結するローカル推論にも「オフライン動作・低遅延・コスト制御」といった利点があります。 本稿では、llama.cppのAndroid向け手順を基に、WSLでのビルドからadbによる配置、端末上での実行までを整理しました。実機で動作した要点と注意点をまとめました。 ※ SLM (Small Language Model)という語もあるみたいなのですが、現状軽量LLMといった呼び方をされるケースが多い印象ですので、本記事でも語としてはLLMを利用します。

世の人々のすなる生成AI開発といふものを...。 生成AIを活用したアプリ開発ではサーバ側APIを呼ぶ構成が主流ですが、端末内で完結するローカル推論にも「オフライン動作・低遅延・コスト制御」といった利点があります。 本稿では、llama.cppのAndroid向け手順を基に、WSLでのビルドからadbによる配置、端末上での実行までを整理しました。実機で動作した要点と注意点をまとめました。 ※ SLM (Small Language Model)という語もあるみたいなのですが、現状軽量LLMといった呼び方をされるケースが多い印象ですので、本記事でも語としてはLLMを利用します。
知識・情報
2025/11/07 UP
- プログラミング
- AIエンジニア
- LLM
やったことまとめ
1.Android端末上でllama.cppのローカル推論が動作し、llama-serverを常駐させた上でUnityから端末内HTTP(SSE)で逐次表示まで確認しました。 2.”量子コンピュータについておしえて”というプロンプトに対し、最初のトークンが推定されるまでに約9秒かかり約3トークン/秒で後続の推論が行われました。
全体像
llama.cpp/docs/Android.mdに記載されている手順に沿ってビルド > 配置 > 端末実行 > アプリ実行 の順に手順を記載していきます。
- WSL(Ubuntu)でllama.cppをAndroid向けにビルド
- 生成された成果物をadbで端末へ配置
- 端末でllama-simple/llama-serverを実行
- 端末内通信でのアプリ利用を確認
環境
ビルド・実行に関係のありそうな環境を示します。
| OS | Windows 11 |
| llama.cppビルドOS | Ubuntu 22.04.2 LTS |
| cmake | 3.22.1 |
| NDK | r27d |
| LLM | Llama-3-ELYZA-JP-8B-q4_k_m.gguf |
| Android OS | 13 |
| Android CPU | Snapdragon 888 |
| CPU 命令セット ※ | ARMv8.4-A |
※ llama.cppビルド時に分かっているとよさげです。Wikipedia等に一覧があります。
1. WSL(Ubuntu)でllama.cppをAndroid向けにビルド
■ SDKとNDKのインストール
Android用のSDK,NDKを必要に応じて追加でインストールします。
- SDKインストール
sudo apt update
sudo apt install android-sdk
- NDKインストール
- https://developer.android.com/ndk?hl=ja > ダウンロードよりバージョンは適宜確認してください
mkdir -p ~/Android
cd ~/Android
wget https://dl.google.com/android/repository/android-ndk-r27d-linux.zip
unzip android-ndk-r27d-linux.zip
■ llama.cppを取得
llama.cppをクローンし、Androidビルド用ディレクトリを生成しておきます。
git clone https://github.com/ggml-org/llama.cpp.git
mkdir -p llama-build-android
cd llama-build-android
■ cmake実行
Android.mdに記載のビルドコマンドはarmv8.7a最適化を有効にしています。実行対象のAndroid端末がSnapdragon 8 Gen 2以降であれば、下記コマンドでビルドして問題ないと思われます。
cmake ../llama.cpp \
-DCMAKE_TOOLCHAIN_FILE=~/Android/android-ndk-r27d/build/cmake/android.toolchain.cmake \
-DANDROID_ABI=arm64-v8a \
-DANDROID_PLATFORM=android-28 \
-DCMAKE_C_FLAGS="-march=armv8.7a" \
-DCMAKE_CXX_FLAGS="-march=armv8.7a" \
-DGGML_OPENMP=OFF \
-DLLAMA_CURL=OFF \
-DGGML_LLAMAFILE=OFF
手元のAndroidはこのバージョンの命令セットに対応していないため、一部フラグを無効化してビルドしました。
cmake ../llama.cpp \
-DCMAKE_TOOLCHAIN_FILE=~/Android/android-ndk-r27d/build/cmake/android.toolchain.cmake \
-DANDROID_ABI=arm64-v8a \
-DANDROID_PLATFORM=android-28 \
-DGGML_OPENMP=OFF \
-DLLAMA_CURL=OFF \
-DGGML_LLAMAFILE=OFF
■ ビルド
カレントディレクトリがllama-build-androidであることを確認した上で、ビルドを実行します。8コアで並列ビルドさせました。
cmake --build . --config Release -j8
ビルド時間は約5分、.so拡張子を持つファイルは全部で30MB程度でした。
2. 生成された成果物をadbで端末へ配置
■ インストール
~/llama-build-android/install_android以下にインストール用の成果物一式を用意します。
cmake --install . --prefix ./install_android --config Release
■ 実機配置
WSL側のADB接続の調整をしていなかったため、以降はWindows 11側のadbを使い生成物を配置 & llama.cppの動作確認を行います。
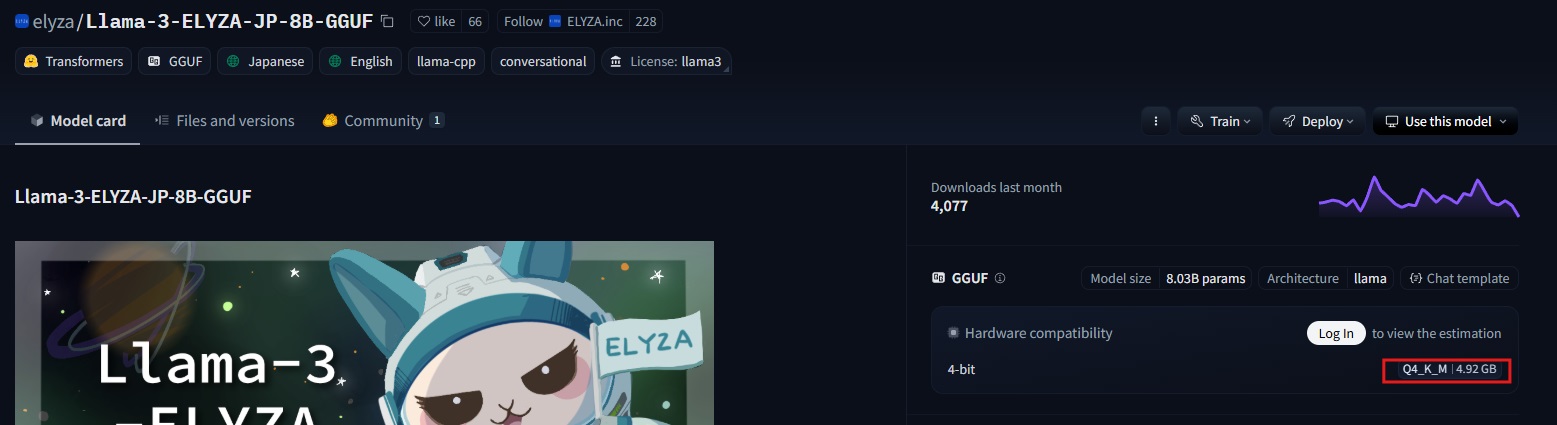
■■ LLMモデルダウンロード
先に利用するLLMモデルをダウンロードしておきます。今回はLlama-3-ELYZA-JP-8Bの4ビット量子化版を取得しました。
■■ Android端末への転送
USBで実機とPCを接続し、ディレクトリを作成しつつ成果物一式&モデルをAndroidに転送します。
$ adb shell "mkdir /data/local/tmp/llama.cpp"
$ adb push "\\wsl.localhost\Ubuntu\home\...\llama-build-android\install_android" /data/local/tmp/llama.cpp/
$ adb push "C:Downloads\Llama-3-ELYZA-JP-8B-q4_k_m.gguf" /data/local/tmp/llama.cpp/
また、このままだと実行権限がないため権限を付与しておきます。
$ adb shell "chmod +x /data/local/tmp/llama.cpp/install_android/bin/llama-simple"
3. 端末でllama-simple/llama-serverを実行
■ llama-simple実行
動作確認としてAndroid内部へadbでアクセスし、llama-simpleを起動します。
$ adb shell
$ cd /data/local/tmp/llama.cpp
$ LD_LIBRARY_PATH=/data/local/tmp/llama.cpp/install_android/lib /data/local/tmp/llama.cpp/install_android/bin/llama-simple -m /data/local/tmp/llama.cpp/Llama-3-ELYZA-JP-8B-q4_k_m.gguf -n 128 -c 512 -p "量子コンピュータの特徴を日本語で説明してください"
実行後出力
<|begin_of_text|>-c 512 -p 量子コンピュータの特徴を日本語で説明してください。
量子コンピュータは、現在の classicalコンピュータと比べて、計算速度や処理能力が格段に優れている新しいタイプのコンピュータです。
従来の classicalコンピュータは、0と1の二進法で情報を処理するため、計算速度や処理能力に限界があります。一方、量子コンピュータは、0と1の重ね合わせを利用して情報を処理するため、計算速度や処理能力が飛躍的に向上します。
量子コンピュータの
main: decoded 128 tokens in 37.51 s, speed: 3.41 t/s
日本語テキストが生成されました! なお、cmakeの段階で命令セットに最適化をしていて端末側が対応していない場合は、このタイミングでエラーが出ます。
■ llama-server実行
同様にサーバモードでも実行してみます。
$ chmod +x /data/local/tmp/llama.cpp/install_android/bin/llama-server
$ LD_LIBRARY_PATH=/data/local/tmp/llama.cpp/install_android/lib nohup /data/local/tmp/llama.cpp/install_android/bin/llama-server -m /data/local/tmp/llama.cpp/Llama-3-ELYZA-JP-8B-q4_k_m.gguf -n 128 -c 512 > server.log 2>&1 &
$ tail -f server.log
実行後出力
...
main: server is listening on http://127.0.0.1:8080 - starting the main loop
srv update_slots: all slots are idle
...
起動が確認できましたので、リッスンしているポートに対してPOSTを実行したところ、streamフラグによる推論毎の動作含めきちんと結果が返ってきました!
- 一括返答
curl -X POST http://127.0.0.1:8080/completion -H "Content-Type: application/json" -d '{"prompt": "こんにちは"}'
- ストリーム返答
curl -X POST http://127.0.0.1:8080/completion -H "Content-Type: application/json" -d '{"prompt": "こんにちは", "stream":true}'
4. 端末内通信でのアプリ利用を確認
■ llama-server常駐
llama-serverの動作が確認できたため、nohup起動を行いバックグラウンドで動作させつつ、待ち受けURLあてにPOSTを行うことでアプリからの利用を試してみます。
cd data/local/tmp/llama.cpp
LD_LIBRARY_PATH=/data/local/tmp/llama.cpp/install_android/lib nohup /data/local/tmp/llama.cpp/install_android/bin/llama-server -m /data/local/tmp/llama.cpp/Llama-3-ELYZA-JP-8B-q4_k_m.gguf -n 128 -c 512 -t 4 > server.log 2>&1 &
■ Unityアプリ作成
Androidアプリということで、Unityで作成したものから通信を試してみます。
UGUIで単純な入力フィールド、ボタン、出力フィールドを用意し、下記スクリプトを適当なGameObjectにアタッチして参照を設定しました。
動作確認用スクリプト
[SerializeField] private TMP_InputField inputField;
[SerializeField] private Button sendButton;
[SerializeField] private TextMeshProUGUI outputField;
private StringBuilder strb = new();
private void Start()
{
sendButton.onClick.AddListener(() => StartCoroutine(PostPromptStream()));
}
public IEnumerator PostPromptStream()
{
strb.Clear();
string url = "http://127.0.0.1:8080/completion";
var input = inputField.text;
string json = $"{{\"prompt\": \"次のユーザからの質問に日本語で端的に答えて:{input}\", \"stream\": true}}";
UnityWebRequest request = new UnityWebRequest(url, "POST");
byte[] bodyRaw = Encoding.UTF8.GetBytes(json);
request.uploadHandler = new UploadHandlerRaw(bodyRaw);
var handler = new LlamaStreamHandler();
handler.SetCallback(OnReceivedText);
request.downloadHandler = handler;
request.SetRequestHeader("Content-Type", "application/json");
yield return request.SendWebRequest();
if (request.result != UnityWebRequest.Result.Success)
Debug.LogError(request.error);
while (!request.isDone)
yield return new WaitForSeconds(0.1f);
strb.AppendLine("");
strb.AppendLine("---了---");
outputField.text = strb.ToString();
}
private void OnReceivedText(string chunk)
{
var isSse = chunk.StartsWith("data:");
if (!isSse)
return;
string jsonPart = chunk.Substring(5).Trim();
var json = JObject.Parse(jsonPart);
string content = json["content"]?.ToString();
strb.Append(content);
outputField.text = strb.ToString();
}
public class LlamaStreamHandler : DownloadHandlerScript
{
private Action<string> onReceivedData;
public LlamaStreamHandler() : base() { }
public void SetCallback(Action<string> action) => onReceivedData = action;
protected override bool ReceiveData(byte[] data, int dataLength)
{
if (data == null || dataLength == 0)
return false;
string chunk = Encoding.UTF8.GetString(data, 0, dataLength);
onReceivedData.Invoke(chunk);
return true;
}
}
■ 実機確認
Build & Runでアプリを実機にインストールして動作させます。
目算になりますが、”量子コンピュータについておしえて”というプロンプトに対し、最初のトークンが推定されるまでに約9秒。全出力(158文字)が完了するまで32秒程度かかりました。日本語1文字1.5トークンと仮定すると、3トークン/秒程度の速度になります。
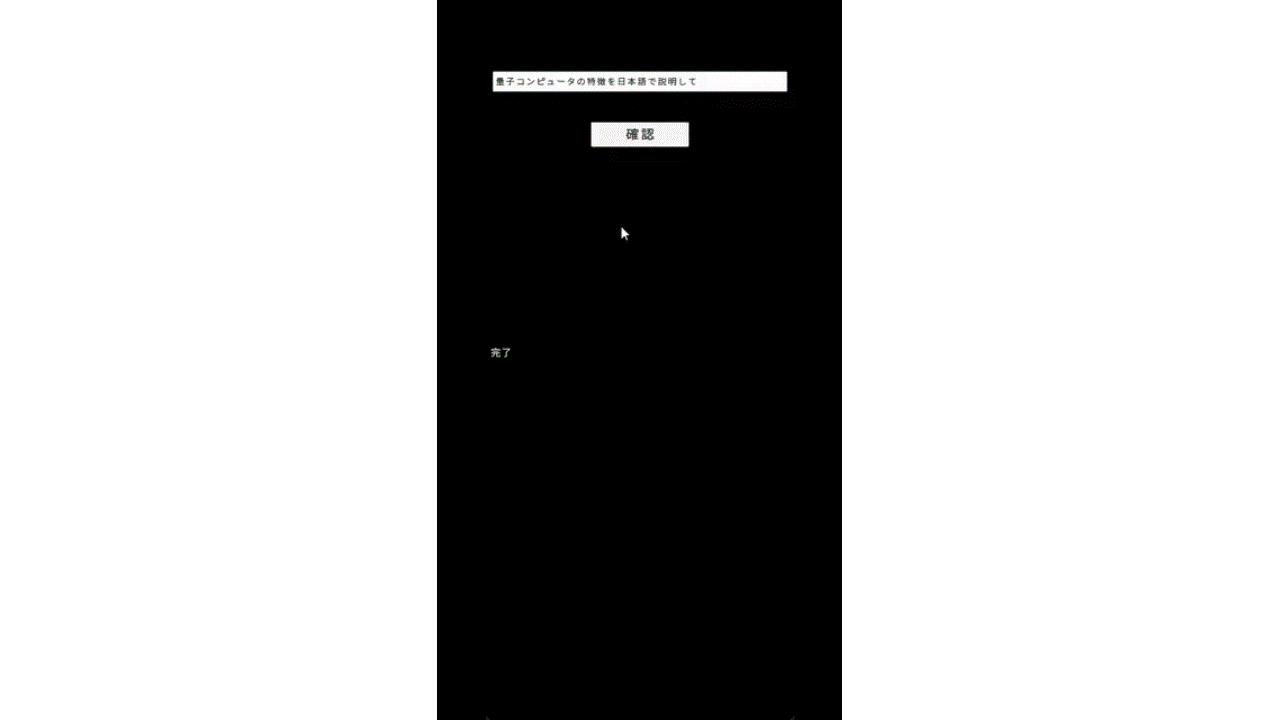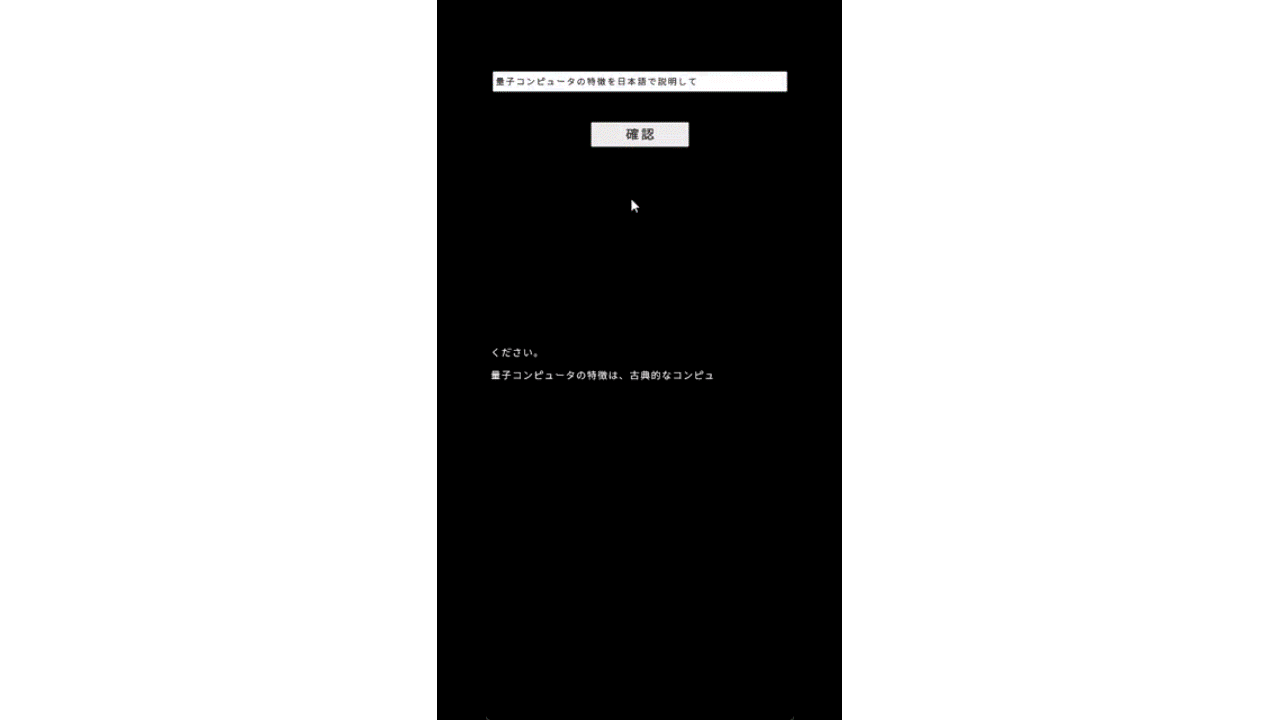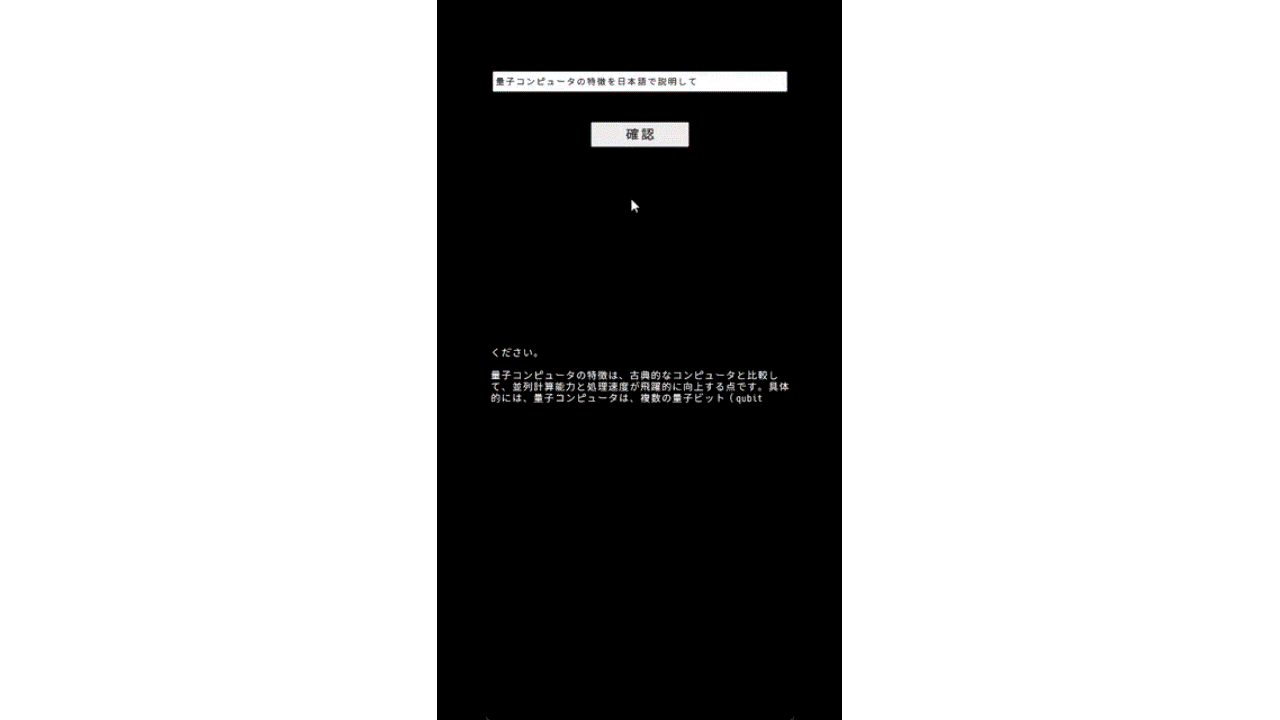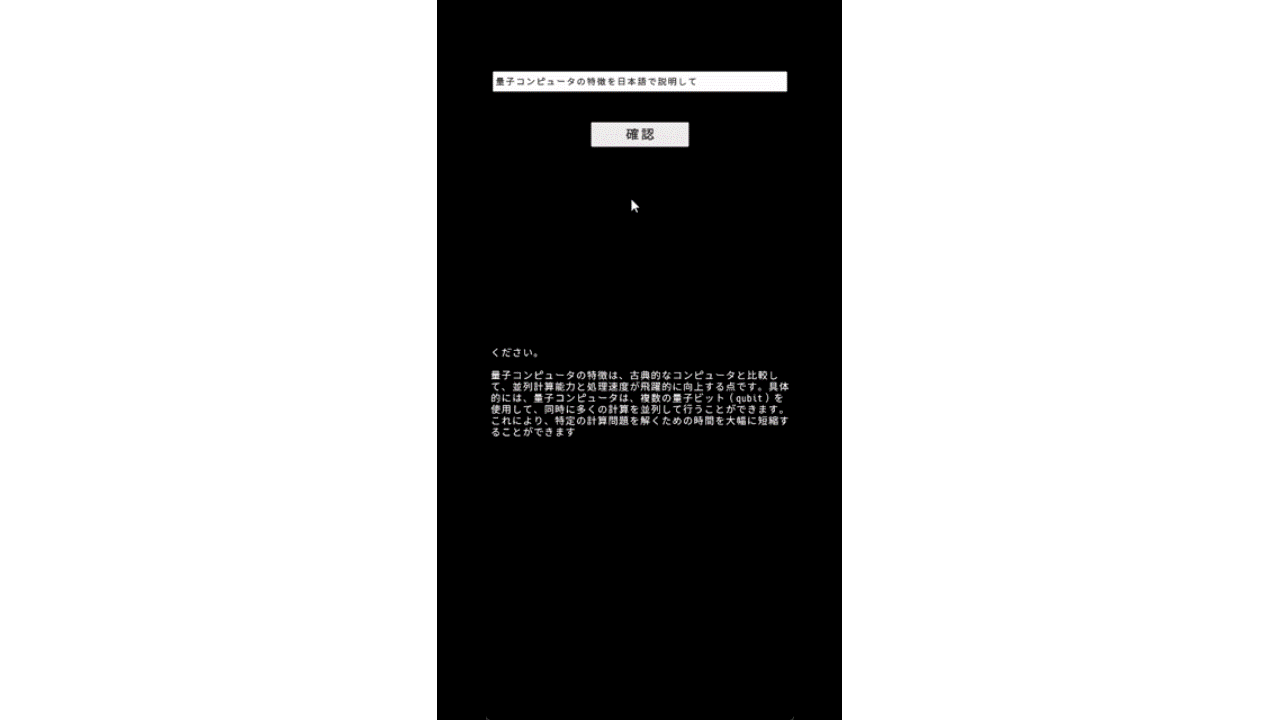
所感
- この方式でも、端末内HTTPのオーバーヘッドは推論(トークン生成)時間に比べ小さいと見ています。端末とモデルの進化で体感速度はさらに改善していくはずです。
- 一般配布には命令セット別ビルドやadb起動など壁があります。一方、端末同梱の設置案件ならバッチ等で運用できますが、推論速度が壁となりそうです。
- 将来的にGoogle Play開発者サービスのオンデバイスLLMがJetpack Composeから使える...のような話が実現するのかな、と妄想しています。
参照
文献
生成AI
この記事を書いたメンバー
クラウドソリューション第1チーム 穂積正隆
※こちらの画像は生成AIで作られており、著作権に問題があるご指摘を頂いた場合はすぐに修正致します。