Unityで実現!Android端末単体でLLM (llama3) を動かす挑戦記
以前の調査で、Android 端末単体でLLMを動作させられることは確認しました。ただしadb shell経由でllama-serverを起動する前提で、端末だけでの自律運用には不向きでした。 本記事では、アプリ内だけでLLMを完結動作させられるかを次の2ステップに分けて検証しました。 1) llama.cpp を Android Studio プロジェクトに組み込み、アプリ単体で推論できるか。 2) その実装を AARとしてパッケージし、Unity アプリ単体で推論できるか。

以前の調査で、Android 端末単体でLLMを動作させられることは確認しました。ただしadb shell経由でllama-serverを起動する前提で、端末だけでの自律運用には不向きでした。 本記事では、アプリ内だけでLLMを完結動作させられるかを次の2ステップに分けて検証しました。 1) llama.cpp を Android Studio プロジェクトに組み込み、アプリ単体で推論できるか。 2) その実装を AARとしてパッケージし、Unity アプリ単体で推論できるか。
知識・情報
2025/12/19 UP
- Unity
- LLM
- AIエンジニア
やったことまとめ
以前の調査はこちら- ステップ1・2ともに動作を確認しました。
- ”量子コンピュータについておしえて。”というプロンプト実行の範囲ではUnityのメインスレッドがブロックされることはありませんでした。
- ただし3トークン/秒程度で推論が進む中、稀に10秒以上次の推論が終わらないタイミングがありましたが、原因を追えていません。
※LLMは約4GBのため、APK/AABへの同梱は現実的ではありません。今回は検証のため外部ストレージに手動配置しています(起動時ダウンロード処理の模擬実装とみなしてください)。
環境| OS | Windows 11 |
| Android Studio | Android Studio Narwhal Feature Drop 2025.1.2 |
| NDK | 29.0.13846066 rc3 |
| LLM | Llama-3-ELYZA-JP-8B-q4_k_m.gguf |
| Android OS | 13 |
| Unity | 6000.0.31f1 |
ステップを細分化した、下記順序にて検証作業を行いました。
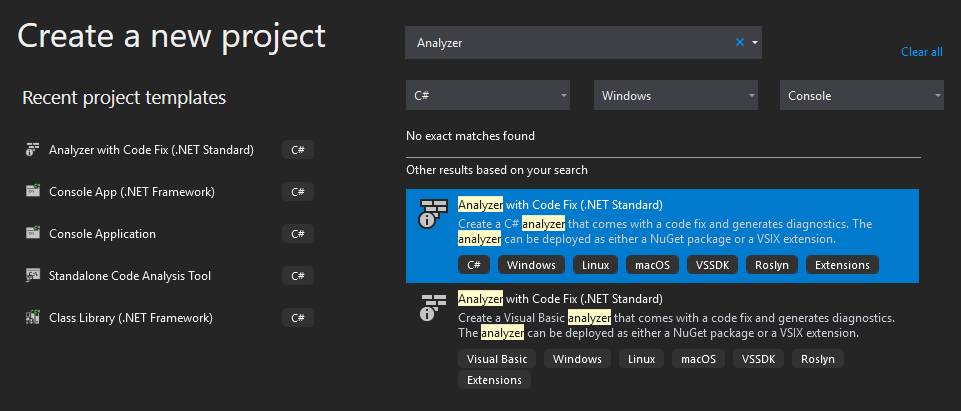
- 1-1. Android向けに構成されたllama.cppのデータを取り込み
- 1-2. llama.cppと連携するためのJNIを追加
- 1-3. 推論用コードを記述
- 1-4. MainActivityから推論コード呼び出し
- 1-5. Android Studio側にUnity連携用処理を追加
- 1-6. AARライブラリを作成しUnityに配置
- 1-7.Unityから推論コード呼び出し
下図に、各ステップにおけるファイルの関連を示します。
始めにAndroid Studioで実験用のプロジェクトを作成します。 今回は下記設定値でプロジェクトを開始しました。
Android向けに構成されたllama.cppのデータを取り込み
- ライブラリ配置
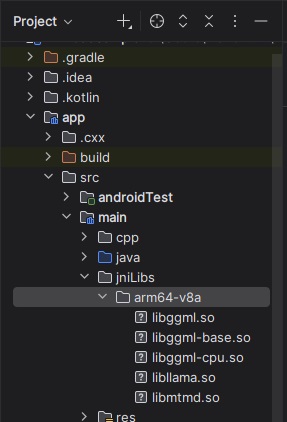
jniLibsディレクトリを新規作成し、arm64-v8a 配下にsoライブラリを配置します。
| ディレクトリ生成 | ライブラリ配置 |
|---|---|
 |
 |
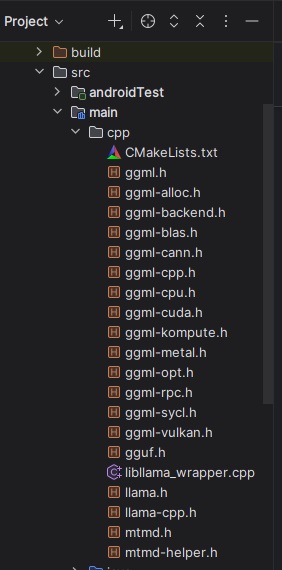
- ヘッダファイル配置
ヘッダファイルをsrc/main/cppに配置します。 次のステップで生成するCMakeListsとlibllama_wrapper.cppも画像には含まれています。
llama.cpp と連携するためのJNIを追加
Kotlin側からllama.cppの機能を呼び出すためにJNI関数を定義します。
新しくlibllama_wrapper.cppを作成しJNI関数を記述していきます。llama.androidを参考にして実装できると思います。最低限下記に対応する関数が用意できていればよいはずです。
- モデルロード
- 初期化
- テキストのトークン化
- 推論
- Sampler生成
- 次トークン推論
- トークンのテキスト化
- 推論パラメータ開放
libllama_wrapper.cppイメージ
#include <jni.h>
#include <cstring>
#include "llama.h"
#include <string>
extern "C" {
// モデルロード
JNIEXPORT jlong JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_loadModel(
JNIEnv *env, jobject obj, jstring path) {
const char *cpath = env->GetStringUTFChars(path, nullptr);
llama_model_params params = llama_model_default_params();
llama_model *model = llama_model_load_from_file(cpath, params);
env->ReleaseStringUTFChars(path, cpath);
return reinterpret_cast<jlong>(model);
}
// コンテキスト生成
JNIEXPORT jlong JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_initContext(
JNIEnv *env, jobject obj, jlong modelPtr) {
llama_context_params params = llama_context_default_params();
llama_context *ctx = llama_init_from_model(
reinterpret_cast<llama_model *>(modelPtr), params);
return reinterpret_cast<jlong>(ctx);
}
// トークン化
JNIEXPORT jint JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_tokenize(
JNIEnv *env, jobject obj, jlong modelPtr, jstring text,
jintArray outTokens, jboolean addSpecial) {
const char *ctext = env->GetStringUTFChars(text, nullptr);
jsize maxTokens = env->GetArrayLength(outTokens);
llama_token *tokens = new llama_token[maxTokens];
const llama_vocab *vocab = llama_model_get_vocab(
reinterpret_cast<llama_model *>(modelPtr));
int32_t n = llama_tokenize(vocab, ctext, strlen(ctext), tokens, maxTokens,
addSpecial, false);
env->ReleaseStringUTFChars(text, ctext);
env->SetIntArrayRegion(outTokens, 0, n, reinterpret_cast<jint *>(tokens));
delete[] tokens;
return n;
}
// 推論(デコード)
JNIEXPORT jint JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_decode(JNIEnv *env,
jobject obj,
jlong ctxPtr,
jintArray tokens,
jint nTokens) {
llama_context *ctx = reinterpret_cast<llama_context *>(ctxPtr);
llama_token *ctokens = reinterpret_cast<llama_token *>(env->GetIntArrayElements(
tokens, nullptr));
llama_batch batch = llama_batch_get_one(ctokens, nTokens);
int32_t ret = llama_decode(ctx, batch);
env->ReleaseIntArrayElements(tokens, reinterpret_cast<jint *>(ctokens), 0);
return ret;
}
// ロジット取得
JNIEXPORT jfloatArray JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_getLogits(
JNIEnv *env, jobject obj, jlong ctxPtr) {
llama_context *ctx = reinterpret_cast<llama_context *>(ctxPtr);
float *logits = llama_get_logits(ctx);
int vocabSize = llama_vocab_n_tokens(
llama_model_get_vocab(llama_get_model(ctx)));
jfloatArray result = env->NewFloatArray(vocabSize);
env->SetFloatArrayRegion(result, 0, vocabSize, logits);
return result;
}
// デフォルトサンプラーチェーン生成
JNIEXPORT jlong JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_createDefaultSampler(
JNIEnv *env, jobject obj) {
auto sparams = llama_sampler_chain_default_params();
sparams.no_perf = true;
llama_sampler *smpl = llama_sampler_chain_init(sparams);
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
return reinterpret_cast<jlong>(smpl);
}
// トークン列のデコード
JNIEXPORT jstring JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_decodeTokens(
JNIEnv *env, jobject obj, jlong modelPtr, jintArray tokens,
jint nTokens) {
llama_model *model = reinterpret_cast<llama_model *>(modelPtr);
const struct llama_vocab *vocab = llama_model_get_vocab(model);
jsize len = nTokens;
jint *tokenArr = env->GetIntArrayElements(tokens, nullptr);
std::string result;
char piece[256];
for (jsize i = 0; i < len; ++i) {
int token = tokenArr[i];
int vocab_size = llama_vocab_n_tokens(vocab);
if (token < 0 || token >= vocab_size) continue;
int piece_len = llama_token_to_piece(vocab,
static_cast<llama_token>(token),
piece, sizeof(piece), 0, false);
piece[sizeof(piece) - 1] = '\0';
result.append(piece, piece_len);
}
env->ReleaseIntArrayElements(tokens, tokenArr, 0);
return env->NewStringUTF(result.c_str());
}
// モデルロード(スレッド数指定版)
JNIEXPORT jlong JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_loadModelWithThreads(
JNIEnv *env, jobject obj, jstring path, jint nThreads) {
const char *cpath = env->GetStringUTFChars(path, nullptr);
llama_model_params params = llama_model_default_params();
params.n_gpu_layers = 0; // CPU専用
// モデルロードの呼び出しが抜けていたため追加
llama_model *model = llama_model_load_from_file(cpath, params);
env->ReleaseStringUTFChars(path, cpath);
return reinterpret_cast<jlong>(model);
}
JNIEXPORT jlong JNICALL
Java_jp_co_pasona_scol1_mahozumi_sample_llm_exp1_LlamaNative_initContextWithThreads(
JNIEnv *env, jobject obj, jlong modelPtr, jint nThreads,
jint nThreadsBatch) {
llama_context_params params = llama_context_default_params();
// スレッド数の設定
params.n_threads = nThreads; // 推論時のスレッド数
params.n_threads_batch = nThreadsBatch; // バッチ処理時のスレッド数
// パフォーマンス関連の設定
params.rope_scaling_type = LLAMA_ROPE_SCALING_TYPE_NONE;
params.pooling_type = LLAMA_POOLING_TYPE_NONE;
params.attention_type = LLAMA_ATTENTION_TYPE_UNSPECIFIED;
// コンテキストサイズの設定
params.n_ctx = 2048; // コンテキストサイズ
params.n_batch = 512; // バッチサイズ
params.n_ubatch = 512; // マイクロバッチサイズ
// メモリ効率化
params.type_k = GGML_TYPE_F16;
params.type_v = GGML_TYPE_F16;
llama_context *ctx = llama_init_from_model(
reinterpret_cast<llama_model *>(modelPtr), params);
return reinterpret_cast<jlong>(ctx);
}
}
あわせて、JNIが参照するライブラリの関係をCMakeListsに記載します。
CMakeLists.txt全文
cmake_minimum_required(VERSION 3.18)
project("llmloadsample")
add_library(
llama_wrapper
SHARED
libllama_wrapper.cpp
)
target_include_directories(
llama_wrapper
PRIVATE
${CMAKE_CURRENT_SOURCE_DIR}
${JNI_INCLUDE_DIRS}
)
add_library(llama SHARED IMPORTED)
set_target_properties(llama PROPERTIES
IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libllama.so
)
find_library(log-lib log)
target_link_libraries(
llama_wrapper
llama
${log-lib}
)
また、JNI 関数を呼び出すための宣言をKotlin側に記載します。ロードするモデルのパスや推論時のプロンプトを渡す以外は、JNI関数呼び出しの薄いラッパーです。
LlamaNative.kt 全文
package jp.co.pasona.scol1.mahozumi.sample.llm.exp1
import android.util.Log
class LlamaNative {
companion object {
init {
System.loadLibrary("ggml-base");
System.loadLibrary("ggml-cpu");
System.loadLibrary("ggml");
System.loadLibrary("mtmd");
System.loadLibrary("llama") // libllama.soをロード
System.loadLibrary("llama_wrapper");
}
}
// ネイティブ関数宣言
external fun loadModel(path: String): Long
external fun initContext(modelPtr: Long): Long
// スレッド数指定版を追加
external fun loadModelWithThreads(path: String, nThreads: Int): Long
external fun initContextWithThreads(modelPtr: Long, nThreads: Int, nThreadsBatch: Int): Long
external fun tokenize(modelPtr: Long, text: String, outTokens: IntArray, addSpecial: Boolean): Int
external fun decode(ctxPtr: Long, tokens: IntArray, nTokens: Int): Int
external fun getLogits(ctxPtr: Long): FloatArray
external fun sampleNextToken(samplerPtr: Long, ctxPtr: Long, idx: Int): Int
external fun decodeToken(modelPtr: Long, token: Int): String
external fun createDefaultSampler(): Long
external fun decodeTokens(modelPtr: Long, tokens: IntArray, nTokens: Int): String
// モデル・コンテキスト管理
var modelPtr: Long = 0
var ctxPtr: Long = 0
fun load(path: String) {
modelPtr = loadModel(path)
ctxPtr = initContext(modelPtr)
}
// スレッド数制御版のload関数
fun loadWithThreadControl(path: String, nThreads: Int = 0, nThreadsBatch: Int = 0) {
val actualThreads = if (nThreads <= 0) {
Runtime.getRuntime().availableProcessors()
} else nThreads
val actualBatchThreads = if (nThreadsBatch <= 0) {
kotlin.math.max(2, actualThreads / 2)
} else nThreadsBatch
modelPtr = loadModelWithThreads(path, actualThreads)
ctxPtr = initContextWithThreads(modelPtr, actualThreads, actualBatchThreads)
}
// Unity環境用の最適化設定
fun loadForUnity(path: String) {
val availableCores = Runtime.getRuntime().availableProcessors()
val unityThreads = when {
availableCores >= 8 -> 4
availableCores >= 4 -> 2
else -> 1
}
val unityBatchThreads = kotlin.math.max(1, unityThreads / 2)
loadWithThreadControl(path, unityThreads, unityBatchThreads)
}
fun tokenizeText(text: String, addSpecial: Boolean = true): IntArray {
val maxTokens = 512
val outTokens = IntArray(maxTokens)
val n = tokenize(modelPtr, text, outTokens, addSpecial)
return outTokens.sliceArray(0 until n)
}
fun infer(tokens: IntArray): Int {
return decode(ctxPtr, tokens, tokens.size)
}
fun getLogitsArray(): FloatArray {
return getLogits(ctxPtr)
}
fun sampleToken(samplerPtr: Long, idx: Int = -1): Int {
return sampleNextToken(samplerPtr, ctxPtr, idx)
}
fun decodeToken(token: Int): String {
return decodeToken(modelPtr, token)
}
fun decodeTokens(tokens: IntArray): String {
return decodeTokens(modelPtr, tokens, tokens.size)
}
}
推論用コードを記述
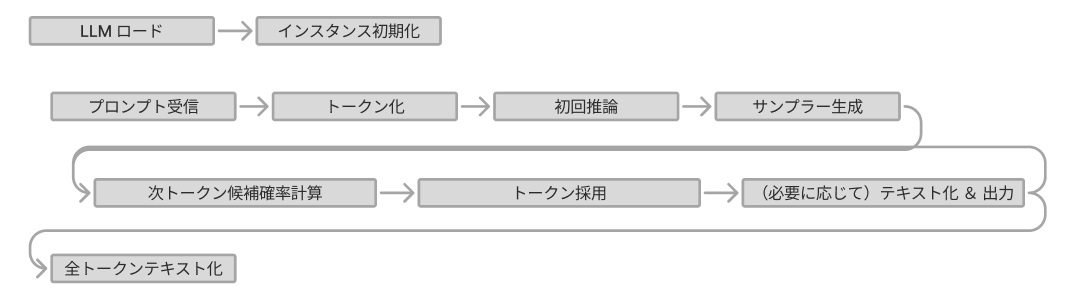
ここまででsoライブラリとの連携は記述できたため、プロンプトを受け取り推論結果を返すコア部分のコードを記述しました。
必要に応じてモデルをロードし、プロンプトに対して初期推論を実施。その後、返答となるトークンを選択するためのSamplerを定義しつつ、1トークンずつ生成するような処理を記載しました。
LlmBridge.kt
package jp.co.pasona.scol1.mahozumi.sample.llm.exp1
import android.util.Log
import kotlinx.coroutines.*
import java.util.concurrent.Executors
object LlmBridge {
// LlamaNativeインスタンスをフィールドに保持
private var llamaInstance: LlamaNative? = null
private var isModelLoaded = false
private val loadLock = Any()
@JvmStatic
public fun generateTextFromPromptAsync(
modelPath: String,
prompt: String,
maxTokens: Int,
gameObjectName: String,
callbackMethodPrefix: String
) {
val availableCores = Runtime.getRuntime().availableProcessors()
val computeThreadPool = Executors.newFixedThreadPool(availableCores) { runnable ->
Thread(runnable).apply {
name = "LlamaCompute-${id}"
priority = Thread.MAX_PRIORITY
isDaemon = false
}
}
val computeDispatcher = computeThreadPool.asCoroutineDispatcher()
val job = CoroutineScope(computeDispatcher + SupervisorJob()).launch {
try {
val llama = getOrCreateLlamaInstance(modelPath)
val tokens = llama.tokenizeText(prompt)
val generatedTokens = tokens.toMutableList()
llama.infer(tokens)
val sampler = llama.createDefaultSampler()
val recentTokens = mutableListOf<String>()
val batchSize = 3
for (index in 0 until maxTokens) {
val loopStartTime = System.nanoTime()
llama.getLogitsArray()
val nextToken = llama.sampleToken(sampler)
generatedTokens.add(nextToken)
val tokenText = llama.decodeToken(nextToken)
recentTokens.add(tokenText)
// バッチサイズに達したらUnityに送信
if (recentTokens.size >= batchSize) {
sendToUnity(gameObjectName, callbackMethodPrefix + "Token", recentTokens.joinToString(""))
recentTokens.clear()
}
llama.infer(intArrayOf(nextToken))
}
// 残りのトークンがあれば送信
if (recentTokens.isNotEmpty()) {
sendToUnity(gameObjectName, callbackMethodPrefix + "Token", recentTokens.joinToString(""))
}
val allText = llama.decodeTokens(generatedTokens.toIntArray())
sendToUnity(gameObjectName, callbackMethodPrefix + "Complete", allText)
} catch (e: Exception) {
sendToUnity(gameObjectName, callbackMethodPrefix + "Error", "Error: ${e.message}")
} finally {
computeThreadPool.shutdown()
}
}
}
private fun getOrCreateLlamaInstance(modelPath: String): LlamaNative {
return synchronized(loadLock) {
if (llamaInstance == null || !isModelLoaded) {
llamaInstance = LlamaNative()
llamaInstance!!.loadForUnity(modelPath)
isModelLoaded = true
}
llamaInstance!!
}
}
}
MainActivityから推論コード呼び出し
あとは任意の位置から推論用コードを呼び出せば、Androidアプリとして呼び出し動作まで確認できます。今回は呼び出し確認が目的のため、OnCreateで推論コードを呼び出し、返り値をLogcatに出力するようにしました。
また、何度か関数の呼び出しエラーが発生したため、soライブラリの追加や関数の調整を行いました。(ChatGPTに聞いた限りではlibllama.soだけでいいと言われていましたが、そんなことは無かった、など)
Android StudioでUnity連携用処理を追記
最後にUnity連携用の関数を追加します。 今回は1つの関数のみ公開し、プロンプトを受け取って推論を開始 > 複数トークンをまとめてUnity側にSendMessageで送付を行う実装としています。
UnitySendMessage については、Android Studio側でUnityファイルへのリンクを作らなくても、反射を try-catch で囲むことで呼び出せました(Unity環境以外では無視)。
Unityから呼び出す部分のスニペット
private fun sendToUnity(gameObjectName: String, methodName: String, message: String) {
try {
val clazz = Class.forName("com.unity3d.player.UnityPlayer")
val method = clazz.getMethod(
"UnitySendMessage",
String::class.java,
String::class.java,
String::class.java
)
method.invoke(null, gameObjectName, methodName, message)
} catch (e: Throwable) {
// Unity環境でなければ何もしない
}
}
AARライブラリを作成しUnityに配置
Androidアプリの動作を確認できたため、このプロジェクトをAARライブラリとして作り直します。Manifest、モジュールレベルのGradleをライブラリ用に変更します。コードイメージ
AndroidManifest.xml
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
</manifest>
モジュールレベルのGradle
plugins {
id("com.android.library")
kotlin("android")
alias(libs.plugins.kotlin.compose)
}
android {
namespace = "jp.co.pasona.scol1.mahozumi.sample.llm.exp1"
compileSdk = 36
defaultConfig {
minSdk = 31
targetSdk = 36
ndk {
abiFilters += listOf("arm64-v8a")
}
externalNativeBuild {
cmake {
cppFlags += "-std=c++17"
}
}
}
buildTypes {
release {
isMinifyEnabled = false
proguardFiles(
getDefaultProguardFile("proguard-android-optimize.txt"),
"proguard-rules.pro"
)
}
}
compileOptions {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
kotlinOptions {
jvmTarget = "11"
}
buildFeatures {
compose = true
}
externalNativeBuild {
cmake {
path = file("src/main/cpp/CMakeLists.txt")
}
}
ndkVersion = "29.0.13846066 rc3"
}
変更を適用すると「アプリ」ではなくなるため、同一モジュールではビルド不可になります。本来はアプリもUnity側も同一ライブラリを呼び出せるよう、MainActivityのみアプリとし、llama.cpp連携部分をライブラリモジュールとすべきなのですが、今回は一緒くたにしてしまっています。
準備ができたら、AARのリリースビルドを実行します(モジュール名は環境に合わせて変更)。Android Studio の Terminal で .\gradlew :app:assembleRelease を実行します。
成功するとapp-release.aarライブラリが作成されます。
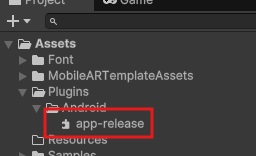
Unity側機能実装
リリースビルドした AARを Plugins/Android 配下に配置し、Kotlinコードを呼び出す処理/Kotlinから呼ばれるコールバックをUnity側に実装しました。
public void CallGenerateTextAsync(string prompt)
{
sendButton.interactable = false;
strb.Clear();
string modelPath = System.IO.Path.Combine(Application.persistentDataPath, "Llama-3-ELYZA-JP-8B-q4_k_m.gguf");
using (var llmClass = new AndroidJavaClass("jp.co.pasona.scol1.mahozumi.sample.llm.exp1.LlmBridge"))
{
llmClass.CallStatic("generateTextFromPromptAsync", modelPath, prompt, 256, "LlmLoader", "OnGenerated");
}
}
// UnitySendMessageで呼ばれるコールバック
public void OnGeneratedToken(string tokenText)
{
strb.Append(tokenText);
outputField.text = strb.ToString();
}
最後に、これらの処理に渡すプロンプト入力用の InputField、開始ボタン、結果表示用の Textを用意し、実機へビルド & Runして動作を確認しました。
所感
- LLMが推論するトークンについて、日本語の場合は日本語の単語毎に推論されるものだと考えていたのですが、内部的にはバイト列になっていることを初めて知りました。
- イメージしていたもの: 『お』 『はよ』 『う』 『ござ』 『い』 『ます』
- 実際:『E3 81 8A E3 81 AF』『E3 82 88』『E3 81 86 E3』『81 94』『E3 81 96 E3 81』『84 E3 81 BE 』『E3 』『81 99』
- ChatGPT 4.1を使ってJNI関数・JNI宣言およびKotlinコードを書いてもらいました。細かい指示なくとも6割くらいは書いてくれましたので、やはり偉大です...。
- 推論コストを考えるとUnityアプリとして組み込むのは難しく、Anrdoid端末におけるGPUへの対応やCPUでの高速実行等の技術進化を待つ必要があると感じました。
参照
文献llama.cpp https://github.com/ggml-org/llama.cpp/tree/master 生成AI
https://copilot.microsoft.com/, Microsoft Copilot
この記事を書いたメンバー
クラウドソリューション第1チーム 穂積正隆
※こちらの画像は生成AIで作られており、著作権に問題があるご指摘を頂いた場合はすぐに修正致します。