ニューラルネットワーク(NN)モデルの軽量化
株式会社パソナWeb/AIチームの朱志翔です。この記事では、ニューラルネットワークモデルの軽量化について、5つの手法(枝刈り、量子化、低ランク分解、転移フィルター、知識蒸留)を紹介しています。各手法は異なるアプローチでモデルのサイズや計算量を削減し、状況に応じて適切な手法を選択または組み合わせることで、性能を維持しながら効果的な軽量化が可能となります。
株式会社パソナWeb/AIチームの朱志翔です。この記事では、ニューラルネットワークモデルの軽量化について、5つの手法(枝刈り、量子化、低ランク分解、転移フィルター、知識蒸留)を紹介しています。各手法は異なるアプローチでモデルのサイズや計算量を削減し、状況に応じて適切な手法を選択または組み合わせることで、性能を維持しながら効果的な軽量化が可能となります。
知識・情報
2024/12/13 UP
- 開発
- AI
NNモデル軽量化の重要性
NNモデル軽量化の手法
NNモデルを軽量化する手法は様々ありますが、以下に5つの手法を紹介します。
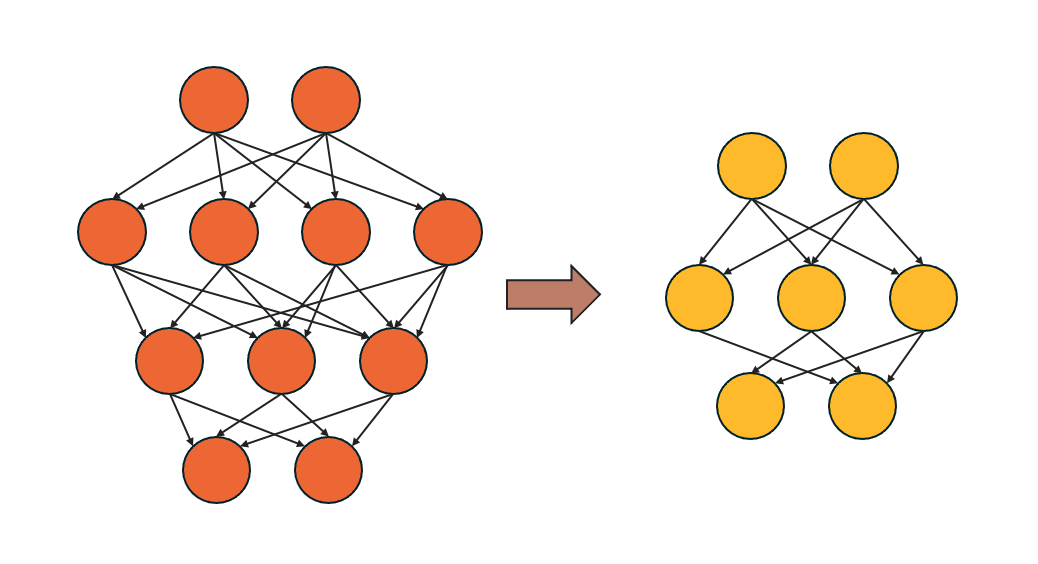
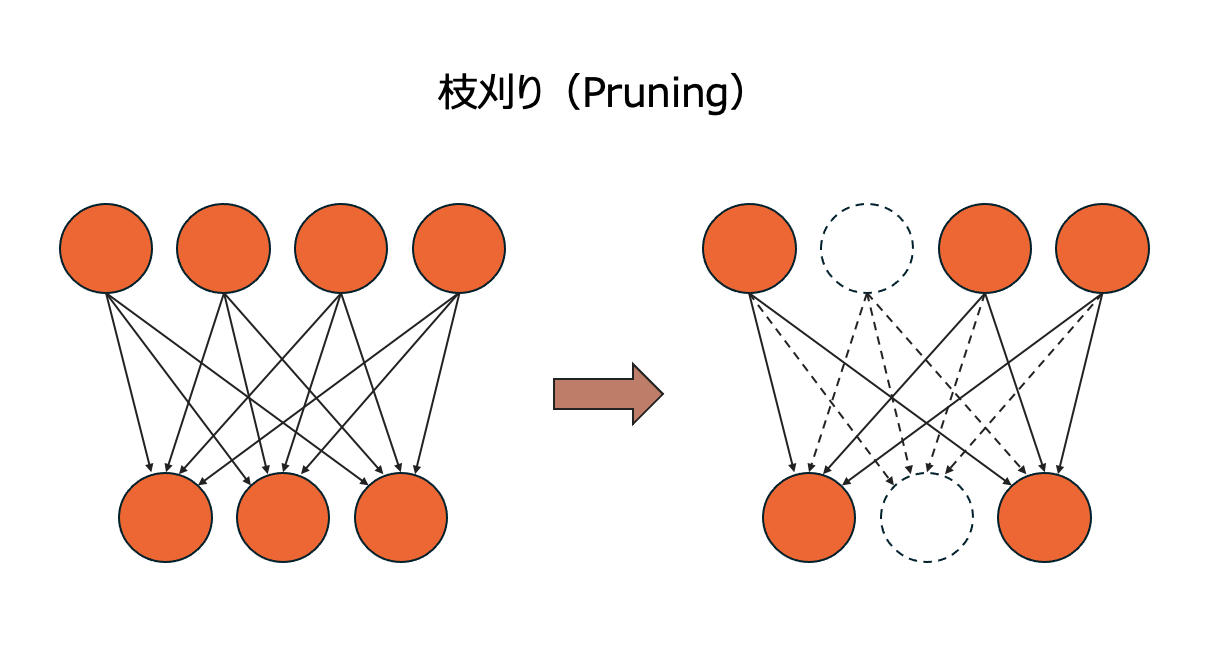
①枝刈り(Pruning)
②量子化(Quantization)
モデル内の重みや活性化関数の値を、より少ないビット数で表現することで、モデルのサイズと計算量を削減する技術です。
通常、これらの値は32ビット浮動小数点数で表現されますが、量子化ではこれを例えば8ビット整数など、より少ないビット数で表現します。これにより、モデルの保存に必要なメモリ容量が削減され、計算も高速になります。
例えば、4個の値 [0.2, -0.5, 1.1, 0.8] を、0〜3の整数値に量子化すると、[1, 0, 3, 2] のように表現できます。このように、少ないビット数で情報を表現することで軽量化を実現します。
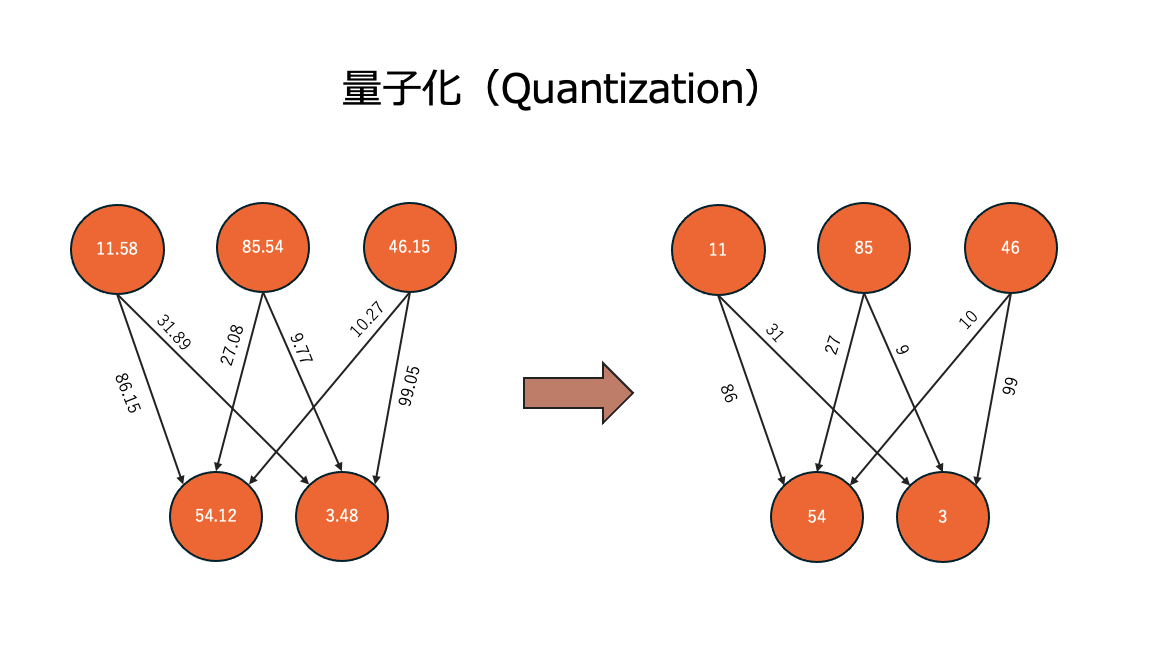
ただし、量子化は情報の精度を落とす操作であるため、モデルの性能低下を引き起こす可能性があります。そのため、性能低下を抑えつつ、どの程度軽量化を実現するかが課題となります。
③ 低ランク分解(Low-Rank Factorization)
ニューラルネットワークの重み行列を低ランクでより小さな行列の積で近似する手法です。この手法は3次元テンソルに構造的な冗長性があるという推測から生まれました。畳み込みカーネルは3次元テンソルとみなされ、全結合層は2次元行列または3次元テンソルとみなされます。
![]()
分解は層ごとに適用され、分析も層ごとに行われます。一つの層のパラメータが固定されると、その上の層は再構成誤差基準に従ってファインチューニングされます。
低ランク分解は、大きな畳み込みカーネルを持つ小規模から中規模のネットワークにおいて、良好な圧縮率と速度の改善が見られます。しかし、近年の新しいネットワークでは1×1の畳み込みが多用されており、低ランク分解の適用には適していません。また、行列分解操作はコストがかかり、層ごとの分解ではグローバルなパラメータ圧縮が困難であり、時には収束のために大幅な再学習が必要となります。
④ 転移フィルター(Transferred Filters)
主に畳み込みニューラルネットワーク(CNN)の軽量化を目的とした手法です。具体的には、CNNモデルにおける大きなフィルターの表現力を、小さな基底フィルターを変換して近似することで、メモリーとディスクに展開するフィルターサイズを削減します。
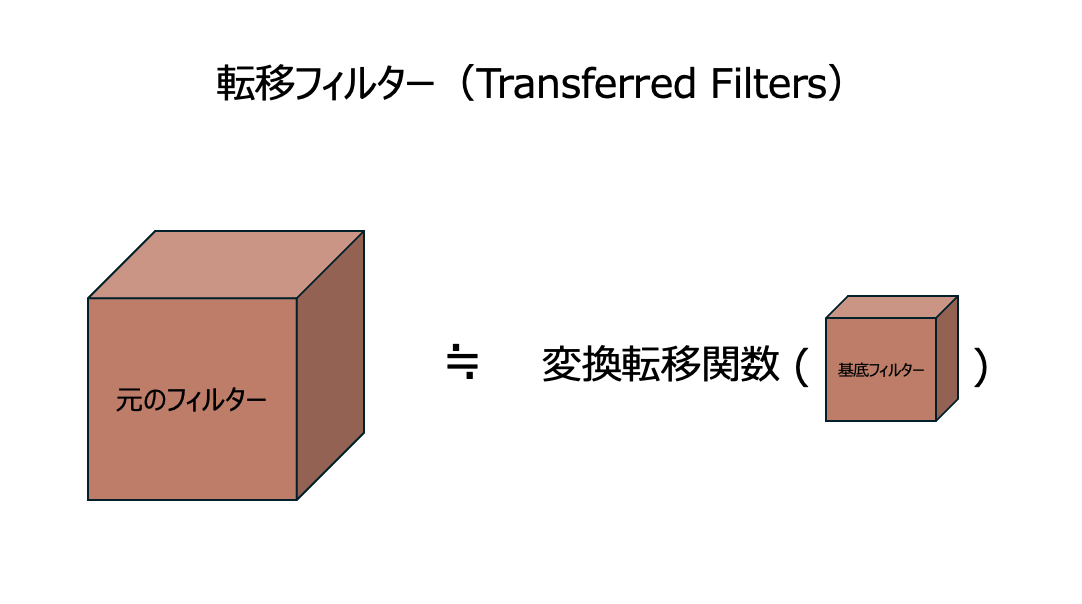
例えば、ある研究によって、CNNの下位層のフィルタは負の相関のある対を形成する傾向があり、正の位相情報と負の位相情報の両方を表現していることを観察しました。この観察に基づき、ReLUの非線形性により下位層のフィルタに冗長性があると仮説しています。そこで、元のフィルターより小さい「基底フィルター」を設計しました。基底フィルターのサイズは元フィルターの半分しかありません。それと反対の位相関係の反転フィルターと組み合わせることで、元フィルターが表す機能を再現することができます。よって、モデルの表現力を維持しつつ、サイズを半分に削減することができます。
また、反転以外、回転や平行移動といった変換を適用することで、CNNフィルターの冗長性を削減する研究もあります。
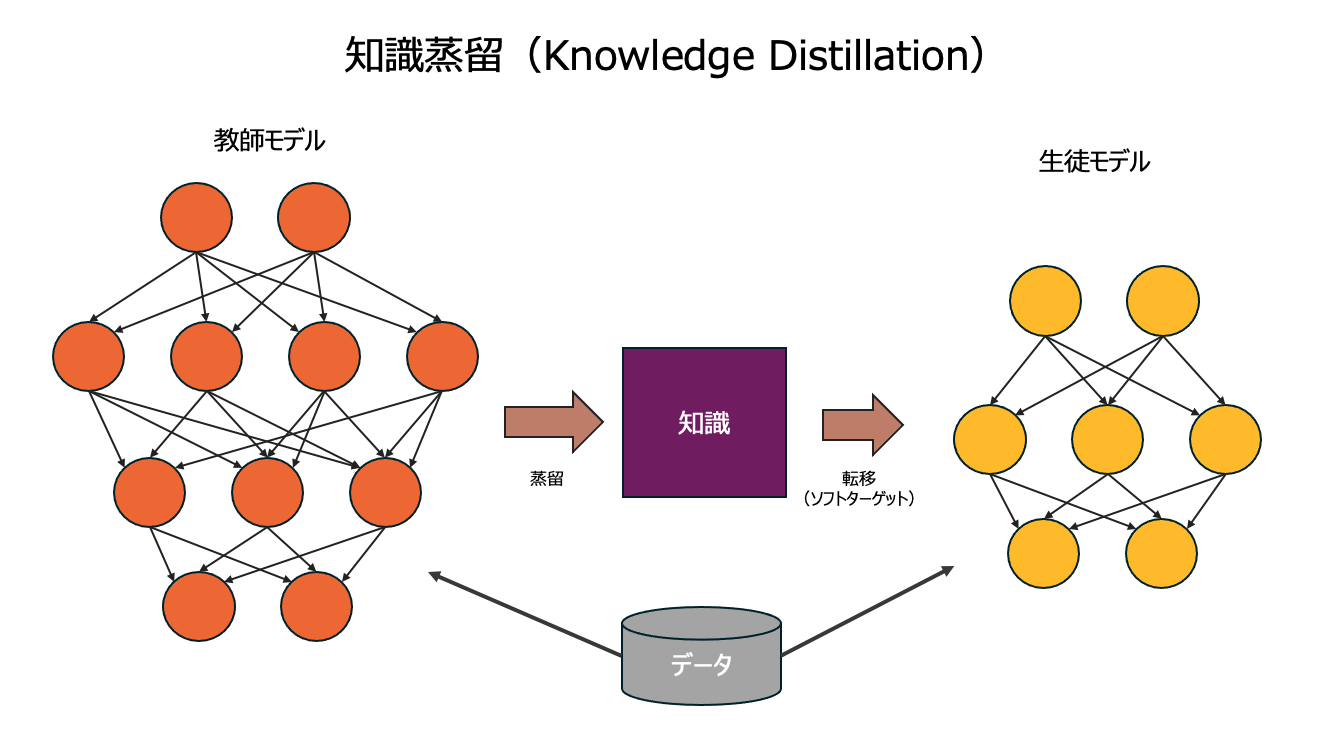
⑤ 知識蒸留(Knowledge Distillation)
大規模で高精度なモデル(教師モデル)の知識を蒸留し、小規模なモデル(生徒モデル)に凝縮して転移させる手法です。例えるなら、熟練職人が弟子に自身の技を伝授するようなイメージです。ニューラルネットワークの文脈では、知識は通常、学習された重みとバイアスを指します。
生徒モデルの設計は非常に重要です。これは通常、教師モデルよりも少ないパラメータで構築されるため、新たに構造を設計しなければなりません。設計においては、層の数を減らす、各層のユニット数を調整するなどの方法でモデルをコンパクトにします。また、MobileNetやShuffleNetといった軽量なアーキテクチャを採用することも効果的です。
設計した生徒モデルを、訓練データの正解ラベル(ハードターゲット)とともに、教師モデルが生成したソフトターゲットを使って学習させます。生徒モデルは、教師モデルの知識を取り入れながら学習を進めることで、小規模でありながらも教師モデルに負けない汎化能力を持つモデルへと成長します。
まとめ
軽量化は、NNモデルを実際のアプリケーションに展開する上で非常に重要な技術です。NNモデルの軽量化により、モバイルデバイスでのモデルのリアルタイム推論性能を向上させたり、サーバー上での計算資源の最適化を図ることができます。
この記事では、NNモデルの軽量化手法を5つ紹介しました。枝刈り、量子化、低ランク分解、転移フィルター、知識蒸留は、それぞれ異なるアプローチでモデルのサイズや計算量を削減します。最適な手法は、モデルの構造やタスク、そしてリソースの制約によって異なり、状況に応じて適切な手法を選択することが重要です。
実際に、弊社でも複数の手法を組み合わせることで、精度を大きく落とさずに数百MBのモデルファイルを数十MBまで軽量化することに成功した事例があります。
なお、NNモデルの軽量化手法は、上記で紹介した5つの手法以外にも、重み共有や行列構造化など、他の手法も存在します。軽量化は、現在も世界中の学者によって活発に研究が進められている分野です。より高度な軽量化手法が開発され、今後さらに高性能で効率的なNNモデルが実現されることが期待されます。
パソナでエンジニアとして働くことにご興味のある方は、ぜひ採用ページもご覧いただき、 各種エントリーフォームへのお申込みもお待ちしております。
https://x-tech.pasona.co.jp/recruit/