AIエンジニアの道:塵も積もれば山となる!~初期学習の落とし穴とデータの重要性~
こんにちは!株式会社パソナWeb/AIチームの朱志翔です。
エンジニアとして働いていると、時に壁にぶつかることがあります。その壁を乗り越えた先に、大きな学びが待っていることがよくあります。
今回は私自身が経験した機械学習プロジェクトでの挫折と、そこから得た貴重な教訓についてお話しします。先輩からいただいた「塵も積もれば山となる」という言葉と共に、AI開発の基礎を改めて叩き込まれた貴重な経験でした。この記事が、同じような課題に直面している方々の一助になれば幸いです。

こんにちは!株式会社パソナWeb/AIチームの朱志翔です。
エンジニアとして働いていると、時に壁にぶつかることがあります。その壁を乗り越えた先に、大きな学びが待っていることがよくあります。
今回は私自身が経験した機械学習プロジェクトでの挫折と、そこから得た貴重な教訓についてお話しします。先輩からいただいた「塵も積もれば山となる」という言葉と共に、AI開発の基礎を改めて叩き込まれた貴重な経験でした。この記事が、同じような課題に直面している方々の一助になれば幸いです。
DX
2025/05/30 UP
- AI
- 開発
- Python
- 仕事内容
事件発生!モデルの精度が思ったより悪い・先輩の二言
私は今、あるAIプロジェクトで、インスタントセグメンテーションモデルの精度向上を担当しています。ある日、モデル学習の結果が思ったより随分悪かったため、データを増やせば解決するだろうと安易に考えていた私は、データの水増しに取り掛かろうとしていました。
計画を進めようとしていた矢先、チームの先輩社員が私の考えを聞いて、こう言いました。
「セグメンテーションの学習に使ったデータの詳細を知りたいです。」
「課題がセグメンテーションなのか、それ以前の問題なのかを切り分けましょう。」
この二言が、私のアプローチを根本から変えることになりました。
先輩のアドバイスに従い、学習データを徹底的にチェックした結果、なんと データに大量の誤り があることが判明しました。
物体検知AIの学習に使用するデータは、写真画像と写真に映っている物体をマークした情報です。写真を見て物体をマークする作業はアノテーション作業ともいいます。
アノテーションの手作業はとても大変なので、こういったデータを大量に集めるのは難しいです。一方、高精度の物体検知AIを作るには、やはり大量の学習データが必要です。
そこで、私たちが取った対策は、手作業で作成した少量のデータをベースに、プログラムで大量の学習データを生成することでした。もっと具体的に言えば、手作業でマークした物体をプログラムで写真から切り抜き、色んな変換(移動や回転)を加え、別の背景写真にコピーします。この対策はデータの水増しともいいます。
つまり、実際に学習に使ったデータはプログラムで生成したものでした。

水増し後の学習データをよく確認したところ、なぜか切り抜いた物体領域が間違っていました。恐らくデータの水増しプログラムに何か不具合があったのでしょう。

このようなデータを増やしても、同じ割合で誤ったデータが生成されることになり、モデルの性能向上にはつながらなかったでしょう。むしろ、誤ったデータがさらに増えることで、モデルの混乱を招く可能性さえありました。
また、私と同時期に、同じプロジェクトに参加している同僚も同じ問題に直面していました。彼もデータ量を増やそうとしていたところ、先輩社員から同様のアドバイスを受け、データの品質問題を発見しました。
同様の問題が複数発生していることに気づいた先輩社員は、チーム全体のために勉強会を開催してくれました。
先輩による勉強会:「初期に学習がうまくできないときの対応」
勉強会は「初期に学習がうまくできないときの対応」というタイトルで開催されました。この会の目的は、単に知識を共有するだけでなく「自分の中にいつでも相談できる同僚を作る」という興味深いコンセプトでした。
先輩社員は、各自が他のメンバーの考え方や仕事の進め方を理解することで、実際には一人で作業していても「○○さんだったらこう言うだろうな、こうするだろうな」という発想ができるようになり、より最適な解決策を見つけられるようになると説明しました。
機械学習の両輪:モデルとデータ
勉強会の中核は、機械学習とディープラーニングにおける基本的な考え方でした。先輩社員はまず、モデルとデータは機械学習の両輪であることを強調しました。どちらかが不十分だと、学習はうまくいきません。

最近はデータ側の方が注目されています。確かに、ビッグデータを活用できる大企業にとっては、データ量が競争優位の源泉になることもあります。しかし、多くの企業にとっては、少数でも質の良いデータを集めることが重要です。スモールデータで良い結果を出すには、データをよく見る必要があるのです。
開発初期のアプローチ:過学習から始める
先輩社員は、機械学習プロジェクトの初期段階での適切なアプローチについて、多くのエンジニアが誤解している点を指摘しました。
「開発の初期は、過学習やデータのリークが起きないと駄目なんです。学習に使ったデータに近いデータ、もしくは学習に使ったデータそのものがちゃんと推論できていないと駄目です。最初は過学習しないと駄目なんです。」
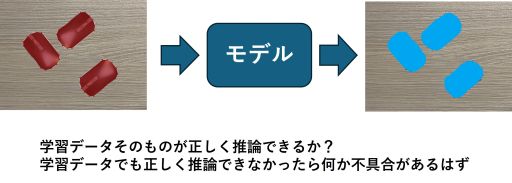
この考え方は、多くの教科書やオンラインリソースでは強調されていないため、私たちにとって目から鱗の瞬間でした。別の先輩社員によれば、まず過学習していることを確認してから、過学習の対策を考えるべきだというのです。
「他のタスクでもまずは簡単な所から入るのは、こういう切り分けをするためです。例えば、物体検知のタスクにおいて、PMがよく『まず簡単な箱(長方形)から』と言うのはこういう意味なんです。」
過学習、実は“悪”じゃない?対策と正しい理解
勉強会では、過学習についての復習も行われました。
「過学習が問題になるのは汎化能力が欲しいからです。しかし、実際には過学習が問題にならないケースもあります。何のために過学習を防ごうとするのかが説明できないと駄目です。」
先輩社員は過学習への対策として3つの方法を紹介しました:
-
1.過学習しにくいモデルを使う 「深いモデルよりもVGG16のような比較的シンプルなモデルの方が過学習しにくい場合があります。」
-
2.データを増やす 「これは最も効果的な方法ですが、増やすデータの質が保証されていることが前提です。」
-
3.データの水増しを行う 「ただし、意味のある水増しをしないと駄目です。何のためにどういうことをやっているか説明できることが重要です。」
対策2と3は本質的に同じです。データの水増し(データ拡張)については、具体的な例も示されました:
- 光の関係でカメラからの画像が変わってしまう → 明るさ、色合いを振る
- 対象物の配置のバリエーションが作りきれない → 反転、回転
- 実際の画像にはノイズが乗る → ノイズ追加
- 対象物が一部しか写らないときがある → 画像の塗り潰し
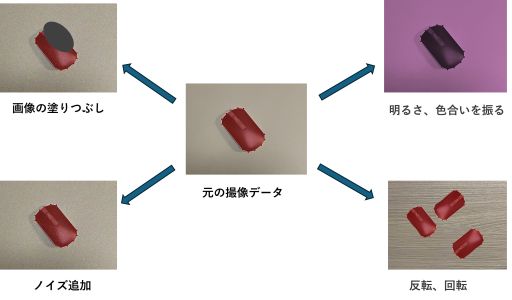
先輩社員は「必ず実際の画像を見て、実際にないケースは作ってはいけません。例えば、実際にぶれることが無いのに、Blurを水増しに使ってはいけないのです。」と注意点も強調しました。
もう一つの対策として、学習に制約を入れる方法(L1ノルムやドロップアウトなど)も紹介しました。
データ管理の重要性
勉強会の最後のセクションでは、データ管理の重要性について詳しく説明がありました。
「学習データはできる限り保存し、後で確認できるようにすることが大切です。できればデータ水増し後の学習データも保存すべきです。保存できない場合も再現性を確保してください。」
具体例として、物体検知モデルの学習において、画像に入っている物体をマークした情報(アノテーション)が教師データとして使われます。そのアノテーションを可視化したファイルも作って保存することが推奨されました。このファイルは学習自体には不要ですが、問題が発生したときにすぐ確認できるようにするための重要な資料になります。
また、データセットのtrainとtestの振り分けについての再現性にも注意が必要です。先輩社員は、ファイル名のパターンを利用した分類方法を提案し、以下のようなコードサンプルも共有してくれました:
def split_train_test(file_list, test_ratio=0.1):
train_files = []
test_files = []
for file in file_list:
# ファイル名の最後の文字をハッシュ的に使用
if int(file[-5]) % 10 < test_ratio * 10:
test_files.append(file)
else:
train_files.append(file)
return train_files, test_files
「このやり方だと後からデータを足していっても、前の分類はそのままで追加したデータの1割だけtestに回ります。乱数を使ってないので再現性が高いのです。最初からここまで考えて仕組みを作ることが大切です。それくらい学習データの扱いは重要なのです。」
また、教科書的なアプローチとして、データを何かしらの形でハッシュ化しその値で分類する方法も基本として紹介しました。
まとめ:データと向き合い、学び続けることの重要性
今回の経験から、AI開発において以下の3つの重要な教訓を得ることができました。
- 1.データの質は量に勝る: 闇雲にデータを増やす前に、手元にあるデータの質を徹底的に検証し、確保することが成功への近道です。
- 2.初期は過学習を恐れない: まずはモデルが基本的な学習データパターンを捉えられているか(過学習しているか)を確認し、そこから汎化性能向上のステップに進むべきです。
- 3.再現可能なデータ管理体制を: 後々の検証や改善のため、学習データとその処理プロセスは、再現可能な形で管理する仕組みを初期段階から構築することが不可欠です。
これらは机上の空論ではなく、プロジェクトの現場で痛感した実践的な学びです。特に、先輩社員が教えてくれた「まずデータを疑う」「簡単なところから始める」という視点は、問題解決へのアプローチを大きく変えてくれました。
先輩社員は勉強会の最後に、「AIエンジニアの道は長い。でも、日々の小さな努力や気づきが、やがて大きな成果につながる」という意味を込めて、私たちのチームメンバーそれぞれの母国の言葉で「塵も積もれば山となる」ということわざを共有してくれました。
- 日本語:塵も積もれば山となる
- 中国語:聚沙成塔
- インドネシア語:Sedikit demi sedikit, lama-lama menjadi bukit.
- 韓国語:티끌 모아 태산

AI開発は、モデルの改良だけでなく、地道なデータとの向き合いが欠かせません。今回の失敗と学びを糧に、これからも一つ一つの課題に丁寧に取り組み、チームと共に成長していきたいと考えています。この記事が、AI開発の現場で奮闘する方々にとって、少しでも参考になれば幸いです。
この記事を書いたメンバー

Web/AIチーム 朱志翔