モデルが速くてもシステムが遅いのはなぜか?高負荷AIシステムを支えるパイプライン設計
AIモデル単体の推論速度は十分に速い。それにもかかわらず、実際のシステムでは映像が遅延する、ロボットの反応が遅れる、AIエージェントの応答が期待より遅い――このような現象は珍しくありません。 本記事では、高負荷AIシステムで発生しやすい性能課題を題材に、モデル最適化だけでは解決できない「システム全体のボトルネック」と、その改善に有効なパイプライン設計について紹介します。 ここでいう高負荷AIシステムとは、リアルタイム映像処理のように連続データを扱うシステムや、AIエージェントのように短時間で多数のリクエストを処理するシステムを指します。

AIモデル単体の推論速度は十分に速い。それにもかかわらず、実際のシステムでは映像が遅延する、ロボットの反応が遅れる、AIエージェントの応答が期待より遅い――このような現象は珍しくありません。 本記事では、高負荷AIシステムで発生しやすい性能課題を題材に、モデル最適化だけでは解決できない「システム全体のボトルネック」と、その改善に有効なパイプライン設計について紹介します。 ここでいう高負荷AIシステムとは、リアルタイム映像処理のように連続データを扱うシステムや、AIエージェントのように短時間で多数のリクエストを処理するシステムを指します。
知識・情報
2026/06/26 UP
- 技術
- 仕事内容
- AI
AIシステムの性能は「モデル」だけでは決まらない
AI開発では、推論時間の短縮に注目が集まりがちです。量子化(Quantization)、枝刈り(Pruning)、TensorRT最適化などにより、モデル単体の処理時間を短くすることは非常に重要です。しかし、実運用のシステムでは、入力、前処理、推論、後処理、出力といった複数の処理が連続して動作します。 このデータの流れが直列的に詰まっていると、たとえ推論処理が高速でも、システム全体としては遅く感じられます。つまり、AIシステムの性能はモデル単体の速度ではなく、データがどれだけ滞りなく流れるかによって大きく左右されます。
典型的なAIパイプライン
多くのAIシステムでは、1つのフレームまたは1つのリクエストが、次のような段階を通過します。
- 入力:カメラ、センサー、ユーザーリクエストなどからデータを受け取る。
- 前処理:画像のサイズ変更、正規化、データ形式変換などを行う。
- 推論:AIモデルを実行し、検出・分類・生成などの処理を行う。
- 後処理:推論結果のデコード、フィルタリング、業務ロジックへの変換を行う。
- 出力:画面表示、ロボット制御、APIレスポンスなどとして結果を返す。
直列処理が引き起こす問題
単純な実装では、これらの処理を下図のように、1つのスレッドで順番に実行します。
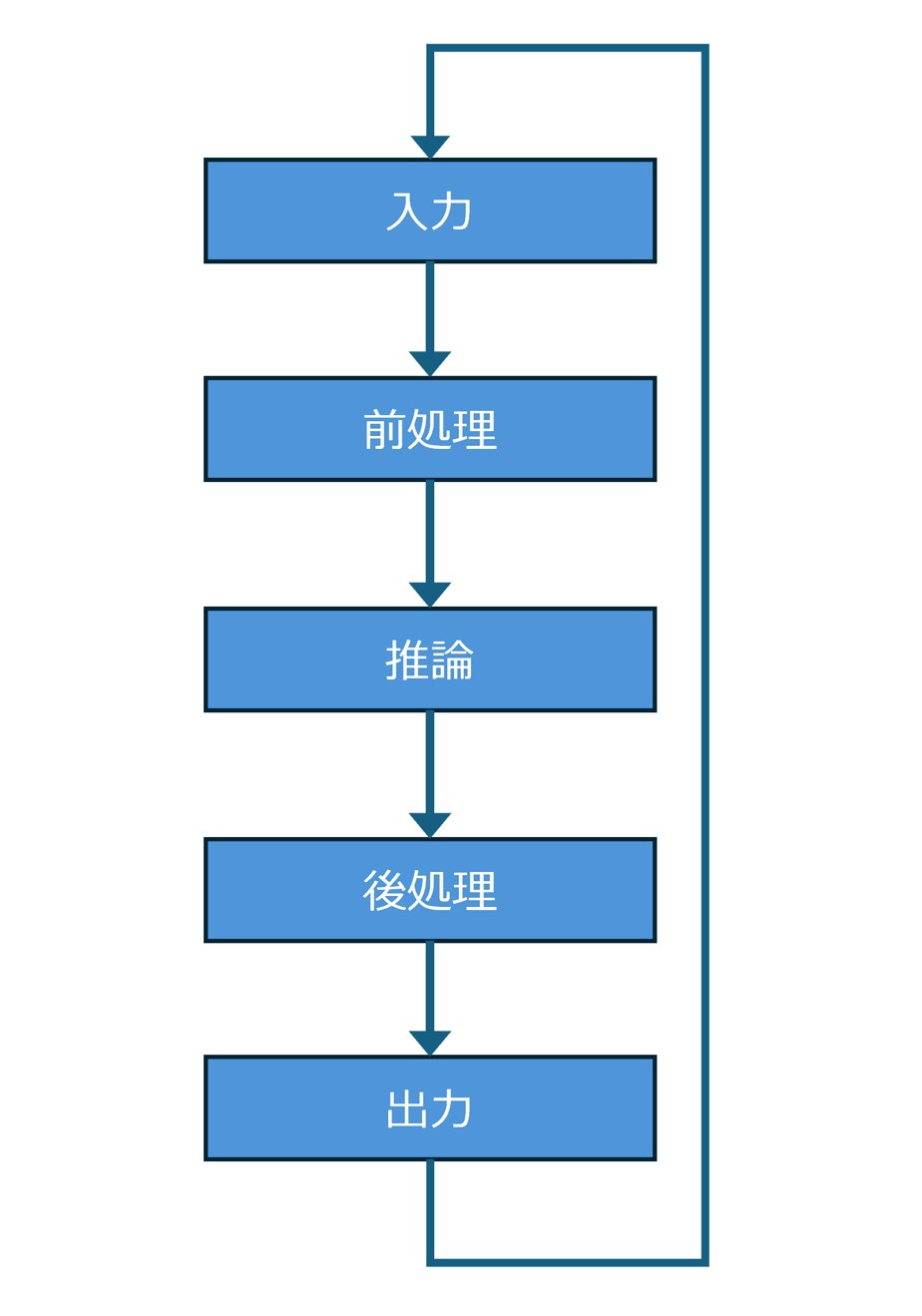
この方法は実装しやすい一方で、各段階が完了するまで次のデータを処理できないため、入力データが増えるほど待ち時間が蓄積しやすくなります。
直列処理のパイプラインでは、下図のように、あるフレームが入力から出力まで完了するまで、次のフレームは待たされます。
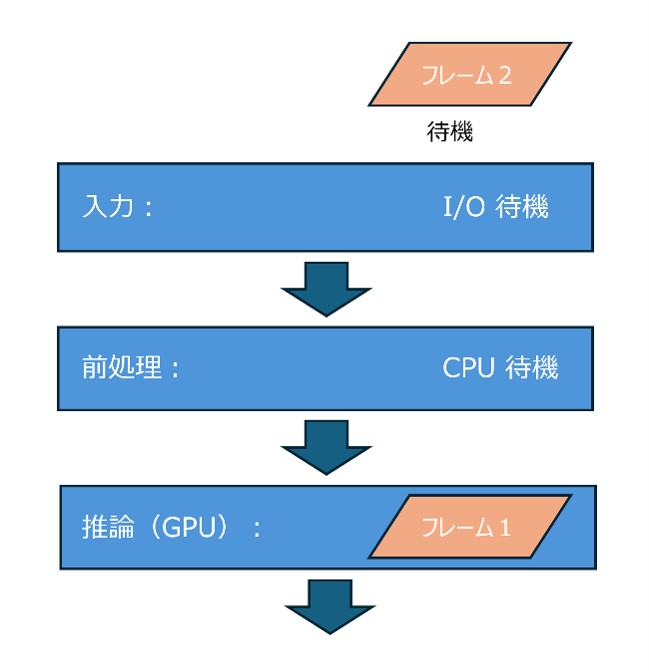
そのため、入力FPSに対して出力FPSが低下したり、リアルタイム映像がカクついたり、重要な瞬間の検出が遅れたりします。
例えば、カメラ映像を使った物体検出では、推論処理そのものが高速でも、画像取得やリサイズ、GPUへの転送、検出結果の描画が直列に並ぶと、最終的な表示は遅れてしまいます。
高並列なAIサービスでも同じです。大量のリクエストが短時間に集中すると、1リクエストずつ順番に処理する構造では、応答待ちのキューが膨らみ、システム全体のレイテンシが悪化します。
この問題の本質は、CPU、GPU、I/Oといった複数のリソースが同時に使われていないことです。ある処理がCPUを使っている間、GPUが待機し、GPUが計算している間に入力処理が止まる。このような待機時間が積み重なることで、モデルは速いのにシステムは遅い、という状態になります。
改善方針:パイプラインを重ねて動かす
改善方法はシンプルです。各処理段階を可能な限り同時に動かし、複数のデータを並行して処理できるようにします。
製造ラインのように、あるフレームが推論中であれば、別のフレームは前処理中、さらに次のフレームは入力中、という状態を作ります。
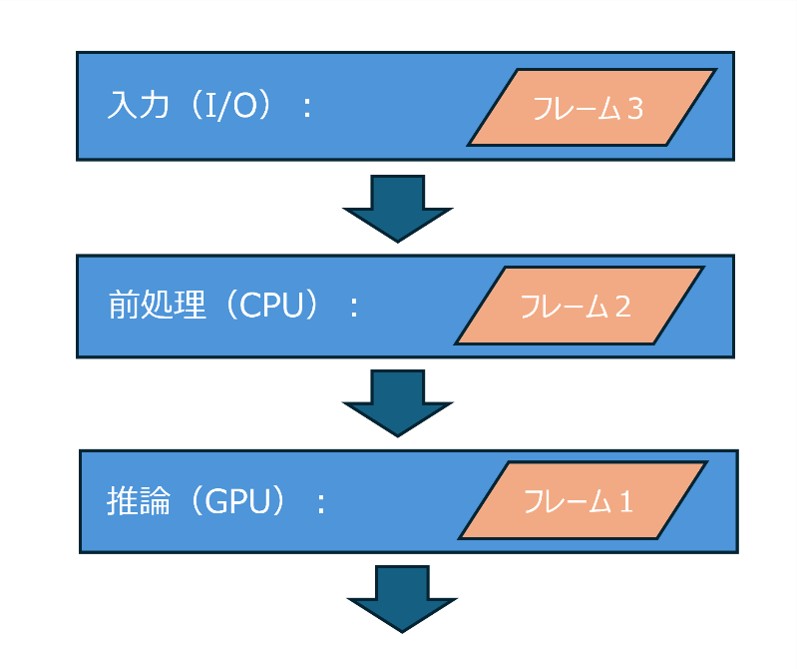
この設計により、CPU、GPU、I/Oを同時に稼働させることができます。
重要なのは、1つの処理を極限まで速くするだけでなく、システム全体として「止まっているリソース」を減らすことです。
CPU側の工夫:マルチスレッド化とキュー設計
CPU側では、入力、前処理、後処理、出力などの各段階を別々のスレッドとして実装することで、処理を並行化できます。処理時間が長い段階には複数スレッドを割り当てるなど、負荷に応じた調整も可能です。
ただし、マルチスレッド化だけでは十分ではありません。スレッド間でデータを受け渡すキューがボトルネックになる場合があります。
一般的なロック付きキューでは、あるスレッドがキューを操作している間、他のスレッドが待たされます。高負荷環境では、この待ち時間がレイテンシ悪化の原因になります。
そのため、実装ではロックフリーキューや、メモリプールを組み合わせることで、スレッド間のデータ受け渡しを安定化できます。これにより、処理の詰まりを減らし、フレーム落ちや応答遅延を抑えやすくなります。
*ロックフリーキューとは、複数のスレッドが同時にデータを受け渡す際に、排他制御(ロック)を使わずに、同時に処理を進められるデータ構造です。代表としてBoost.Lockfreeやcameron314/concurrentqueueなどのライブラリが挙げられます。
GPU側の工夫:CUDA Streamによる重ね合わせ
GPU処理でも同じ考え方が有効です。CUDAを用いた処理は、一般的に
- CPUからGPUへのデータ転送
- GPU上での計算
- GPUからCPUへの結果転送
という段階に分かれます。
これらを毎回同期的に実行すると、データ転送中はGPUコアが待機し、計算中は転送処理が待機する状態になります。 下図は、GPUに長時間の待機状態が見られる典型的なNsightプロファイルの結果です。
オレンジ色の「Executi...」ブロックは計算処理(TensorRTで実装)に費やされた時間、赤色の「cudaM...」ブロックはデータ転送(cudaMemcpy API)に費やされた時間を示しています。
計算処理間、およびデータ転送間に長い間隔があることがわかります。

CUDAストリームを活用すると、複数の処理列を非同期に実行できます。
例えば、あるフレームがGPU上で推論されている間に、別のフレームのデータをGPUへ転送し、さらに別のフレームの結果をCPUへ戻す、といった重ね合わせが可能になります。
CUDAの非同期実行では、ホスト処理、デバイス計算、ホスト・デバイス間のメモリ転送を重ねて実行できるため、アイドル時間の削減に有効です。
実際の効果はGPUの世代、メモリ転送方式、ストリーム数、同期方法に依存するため、Nsightなどのプロファイリングツールで計測しながら調整することが重要です。
下図は、Nsightのプロファイル結果のもう一つの典型的な例で、計算処理間の待機時間が大幅に削減されていることを示しています。メモリ技術が適用されているため、データ転送はほぼ発生しません。

設計で重視すべきポイント
- モデル単体の推論時間だけでなく、入力から出力までの総レイテンシを見る。
- CPU、GPU、I/Oのどこに待機時間があるかを計測する。
- 各段階を並行実行できるようにパイプラインを分離する。
- スレッド間通信では、ロックやメモリ確保のコストに注意する。
- CUDA ストリームや非同期APIを活用し、GPU内部でも処理を重ねる。
- 最終的には、推測ではなくプロファイリング結果に基づいて調整する。
まとめ
AIシステムの性能改善では、モデル最適化だけに注目すると本質的な課題を見落とすことがあります。
実運用で重要なのは、入力から出力までのデータフローを設計し、CPU、GPU、I/Oを継続的に稼働させることです。
マルチスレッド化、ロックフリーキュー、メモリプール、CUDAストリームといった技術は、単なる高速化テクニックではありません。
高負荷なAIシステムを安定して動かすためのシステム設計そのものです。
当社では、このような実装レベルとシステム設計レベルの両面からAIシステムの性能課題に取り組んでいます。
モデルを速くするだけでなく、システム全体を止めずに動かし続けること。それが、実用的なAIプロダクトを支える重要な技術力です。
この記事を書いたメンバー

AIソリューションチーム 朱