【初心者向け】PythonでWebスクレイピングをしよう!
実働するサンプルコードをもとに、Pythonを用いたWebスクレイピングについて詳しく解説していきます。

実働するサンプルコードをもとに、Pythonを用いたWebスクレイピングについて詳しく解説していきます。
スキルアップ
2020/12/22 UP
- プログラミング
- SE資格・スキル
- Python
- Web
業務に必要な情報を自動的にWebから収集して、整理してくれるプログラムやサービスがあればいいのに、と考えたことはありませんか?実はPythonを使用すると、比較的簡単に自分で情報を収集するプログラムを作ることができます。
このような機能のことは「Webスクレイピング」と呼ばれています。PythonというとAI開発や深層学習のイメージが強い人も多いでしょう。しかし、Pythonはもともとデータの収集と分析を得意とするプログラミング言語なので、Webスクレイピングも得意分野の一つなのです。
ここでは実働するサンプルコードをもとに、Pythonを用いたWebスクレイピングについて詳しく解説していきます。

Webスクレイピングとは
Webスクレイピングとは、Webページから情報を取得することを指します。Pythonを用いることで、取得だけでなく、取得した情報をExcelやGoogleスプレッドシートなどに整理し、利用できるようにすることも可能です。
WebスクレイピングをするにはPythonとWebの基礎知識が必要になりますが、決して難しいものではありません。原理を理解することで、自分で使いやすいシステムを構築することができます。
Pythonで使えるWebスクレイピングのライブラリ
PythonにはWebスクレイピングに使えるライブラリが用意されています。今回は代表的な3つのライブラリについて紹介していきます。
BeautifulSoup
HTMLやXMLからデータを引き出せるライブラリです。Pythonでクローラーを作成する際によく使用されるライブラリですが、BeautifulSoup単体ではスクレイピングはできないため、HTTP通信ができるモジュールやCSVにエクスポートする他のライブラリと組み合わせて使用します。
Scrapy
クローラーを実装・運用するために必要となる機能を持つ、アプリケーション全体を実装するためのフレームワークです。Webスクレイピング用に設計されましたが、APIを使用したデータ抽出や汎用クローラーとして使用することも可能です。
Selenium
Webブラウザの操作を自動化するフレームワークです。本来はWebアプリケーションのUIテストを自動化するために開発されましたが、ブラウザの操作をコードで記述して自動化できる利便性の高さからタスクやWebサイトのクローリングなどに転用されています。
PythonでWebスクレイピングをしてみよう!
それでは実際にPythonでWebスクレイピングをするプログラムを書いてみましょう。
今回紹介しているサンプルコードは、すべて実行できるサンプルになっており、「https://www.pasonatech.co.jp/」にアクセスし、タイトルタグを取得する処理をおこなっています。手元で実行する場合は、URLを適切なものに変更してください。
urllib.requestを利用したWebスクレイピング
PythonにはURLを扱うためのモジュールとして、いくつかのモジュールをまとめたurllibモジュールパッケージが標準で付属しています。今回はこの標準モジュールのうち、urllib.reguestモジュールを利用してWebスクレイピングをおこないます。早速サンプルコードを見ていきましょう。
from urllib import request
response = request.urlopen('https://www.pasonatech.co.jp/')
content = response.read()
response.close()
html = content.decode()
title = html.split('<title>')[1].split('</title')[0]
print(title)
まずurllib.request.urlopen関数でURLをオープンします。この関数でURLをオープンすると、サーバからはhttp.clientモジュールで定義されているHTTPResponseクラスのオブジェクトが返送されます。
続いてreadメソッドを使用してWebページの内容(ソースコード)を取得し、URLをクローズします。
ここまでの操作で取得したページの内容はbytesオブジェクト(バイト列)になっているため、decodeメソッドで文字列(str)にデコードします。
最後に、文字列として取得できたデータから、今回はタイトルタグを取得するため、文字列操作でタイトルタグを検索して取得し、出力します。
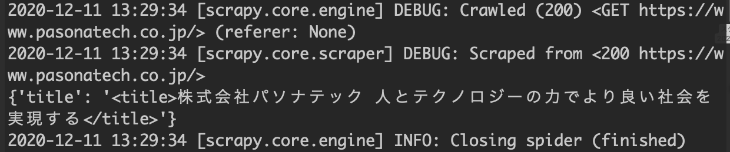
実行結果は次のようになります。実行すると、HTMLからタイトルをスクレイピングして出力します。

BeautifulSoupを使用したWebスクレイピング
ここからは、BeautifulSoupを使用したWebスクレイピングのサンプルコードを見ていきましょう。BeautifulSoupを使用すると、標準のurllibモジュールを使用するよりも簡潔なコードでWebスクレイピングを構築できます。
前項で解説したとおり、BeautifulSoupは単体ではHTTPへの通信機能を持たないため、別のライブラリやパッケージと組み合わせて使用します。今回は「requests」というリクエスト用のパッケージを読み込み、URLを渡すことでWebページを読み込みます。
まずrequestsとBeautifulSoupのライブラリをインポートします。続いて今回取得したいWebサイトのURLをrequestsのgetメソッドで展開してコンテンツを取得します。
取得したコンテンツをresponseに格納してBeautifulSoupに渡し、responseの内容を解析します。最後に解析した内容をfindメソッドで検索して、get_textでテキストを取得し、出力します。
import requests
from bs4 import BeautifulSoup
response = requests.get('https://www.pasonatech.co.jp/')
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').get_text()
print(title)
なお、実行時に以下のようなエラーが出る場合、requestsやBeautifulSoupのモジュールがないため、pip installなどを用いてインストールしてください。
ModuleNotFoundError: No module named 'requests' ModuleNotFoundError: No module named 'bs4'
Scrapyを使用したWebスクレイピング
ScrapyはWebスクレイピング用に開発されたフレームワークなので、標準モジュールやBeutifulSoupを使用したWebスクレイピングよりも簡単に、かつ多機能なWebスクレイピングを作成できます。
まず、
scrapy startproject test1
でプロジェクトを作成し、ファイルを編集します。
Scrapyがインストールされていない場合、下記のコマンドでインストールします。
pip install scrapy scrapy version
プロジェクトを作成したら、次のコマンドで、spiderを作成します。
cd test1 scrapy genspider test2 pasonatech.co.jp
これでセッティングが完了しました。続いて、クローラーの部分のコードを修正します。
まずは、自動で作成されているitems.pyを次のソースコードに修正します。
import scrapy
class Test1Item(scrapy.Item):
title = scrapy.Field()
クローラーの実行部分のソースコードも修正します。spiders/test2.py がこれに当たります。
import scrapy
from test1.items import Test1Item
class Test2Spider(scrapy.Spider):
name = 'test2'
allowed_domains = ['pasonatech.co.jp']
start_urls = ['https://www.pasonatech.co.jp/']
def parse(self, response):
return Test1Item(
title = response.css('title').extract_first(),
)
ここまでで、https://www.pasonatech.co.jp/ にアクセスし、titleタグを取得するという設定が完了しています。
あとは、クローラーを実行するだけですので、
scrapy crawl test2
で実行すると、結果が確認できます。
Webスクレイピングの注意点
Webスクレイピングは、情報を収集するためにWebサイトに頻繁にアクセスします。アクセスする頻度によっては、Webサイトが設置されているサーバに大きな負荷をかけ、他のユーザーがアクセスしにくくなったり、サーバがダウンしてしまう、いわゆるDOS攻撃(Denial-of-service attack)になってしまうケースもあります。
Webスクレイピングをおこなう際には、DOS攻撃にならないよう注意し、アクセスする間隔や頻度を調整するように気を付けましょう。悪意の有無に関わらず、DOS攻撃はサーバ負荷が大きく、アクセス先のWebサイトが設置されているサーバが共有の場合、最悪のケースでは他のユーザーを保護するためサイトがサーバから削除されることもあります。
あくまで収集する情報を提供してもらっているという意識を忘れず、相手に迷惑をかけないプログラミングを心がけましょう。
PythonならWebスクレイピングは簡単!

Webスクレイピングに利用できるライブラリやフレームワークには、タグを操作する関数が他にも多数用意されています。また、文字列操作の関数も多く、取得したソースから必要な情報を検索して抽出し、整理して読みやすい形で出力、保存する機能も簡単に実装できます。
情報を取得するサイトに負荷をかけないよう注意しながら、業務に便利なWebスクレイピングを作成してみましょう。